
浅谈模型训练的权利要求的撰写
2024-04-26文/北京集佳知识产权代理有限公司 冯柳伟
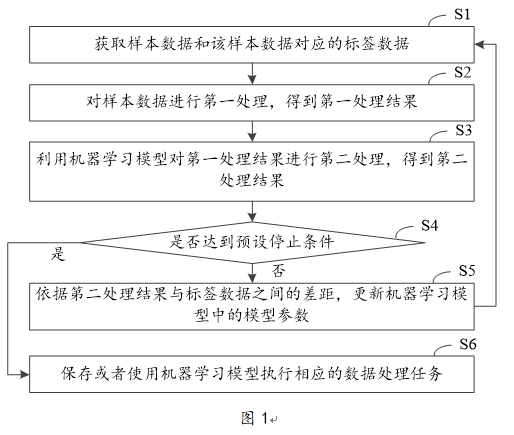
涉及人工智能的发明专利申请,有时需要在权利要求书中布局用于保护模型训练过程的权利要求。其中,权利要求书应当以说明书为依据,清楚、简要地限定要求专利保护的范围。然而,因模型训练过程通常采用循环迭代方式进行实现,因此如何清楚地撰写出用于保护模型训练过程的权利要求是专利代理师在进行专利申请代理过程中需要着重考虑的问题。本文将结合图1所示的模型训练过程分享一些撰写方式以及这些撰写方式的优缺点。
撰写方式一
1.一种模型训练方法,其特征在于,所述方法包括:
步骤1,获取样本数据和所述样本数据对应的标签数据;
步骤2,对所述样本数据进行第一处理,得到第一处理结果;
步骤3,利用机器学习模型对所述第一处理结果进行第二处理,得到第二处理结果;
步骤4,判断是否达到预设停止条件,若否,则依据所述第二处理结果和所述标签数据之间的差距,更新机器学习模型中的模型参数,并继续执行所述步骤1至所述步骤4;若是,则保存或者使用所述机器学习模型执行相应的数据处理任务。
撰写方式一的优缺点以及建议
优点:撰写方式一能够清楚的限定出所需保护的模型训练过程。
缺点:
(1)普适性弱,其理由为:如果模型训练过程中各个步骤之间的时序性比较弱,如一些步骤之间没有必然的先后执行顺序等,则采用撰写方式一所撰写的权利要求容易无法覆盖一些可能的实施方式,如此导致权利要求的保护范围受到影响。
(2)限定性太强,其理由为:①“判断是否达到预设停止条件”这一步骤的执行时间通常对模型训练效果所产生的影响不大,以使这一步骤的执行时间可以灵活地设置,如设置在更新之前或者设置在更新之后等,从而使得采用撰写方式一所撰写的权利要求容易无法覆盖一些可能的实施方式,如此导致权利要求的保护范围受到影响。②非首轮训练过程中所执行的步骤也是可以灵活设置的,如非首轮训练过程中所执行的步骤包括图1中S1-S4,或者,非首轮训练过程中所执行的步骤包括图1中S2-S4,如此使得采用撰写方式一所撰写的权利要求容易无法覆盖一些可能的实施方式,从而导致权利要求的保护范围受到影响。
(3)不清楚,其理由为:因“判断是否达到预设停止条件”这一技术特征中出现的“预设停止条件”这一内容属于自造词,以使该技术特征无法准确地表示出何时停止训练,从而使得采用撰写方式一所撰写的权利要求的保护范围不清楚,进而使得日后可能会面临一些风险。
建议:除非必要,本文不推荐撰写方式一。
撰写方式二
1.一种模型训练方法,其特征在于,所述方法包括:
获取样本数据和所述样本数据对应的标签数据;
对所述样本数据进行第一处理,得到第一处理结果;
利用机器学习模型对所述第一处理结果进行第二处理,得到第二处理结果;
依据所述第二处理结果和所述标签数据之间的差距,更新机器学习模型中的模型参数,并继续执行所述获取样本数据和所述样本数据对应的标签数据的步骤及其后续步骤,直至在达到预设停止条件时,保存或者使用所述机器学习模型执行相应的数据处理任务。
撰写方式二的优缺点以及建议
优点:相对于撰写方式一,更简要并且满足“判断是否达到预设停止条件”这一步骤的执行时间的灵活性要求。
缺点:
(1)不清楚,其理由为:①因“继续执行所述获取样本数据和所述样本数据对应的标签数据的步骤及其后续步骤”这一技术特征中出现的“及其后续步骤”这一内容比较含糊,如“其”这个字指代谁、“后续步骤”是指哪些步骤等,以使采用撰写方式二所撰写的权利要求的保护范围不清楚,从而使得日后可能会面临一些风险。②因“在达到预设停止条件时”这一技术特征中出现的“预设停止条件”这一内容属于自造词,以使该技术特征无法准确地表示出何时停止训练,从而使得采用撰写方式二所撰写的权利要求的保护范围不清楚,进而使得日后可能会面临一些风险。
(2)限定性强,其理由为:非首轮训练过程中所执行的步骤也是可以灵活设置的,如非首轮训练过程中所执行的步骤包括图1中S1-S4,或者,非首轮训练过程中所执行的步骤包括图1中S2-S4等,如此使得采用撰写方式二所撰写的权利要求容易无法覆盖一些可能的实施方式,从而导致权利要求的保护范围受到影响。
建议:除非必要,本文不推荐撰写方式二。
撰写方式三
1.一种模型训练方法,其特征在于,所述方法包括:
获取样本数据和所述样本数据对应的标签数据;
对所述样本数据进行第一处理,得到第一处理结果;
利用机器学习模型对所述第一处理结果进行第二处理,得到第二处理结果;
依据所述第二处理结果和所述标签数据之间的差距,更新机器学习模型中的模型参数,并继续执行所述获取样本数据和所述样本数据对应的标签数据的步骤,直至在达到预设停止条件时,保存或者使用所述机器学习模型执行相应的数据处理任务。
撰写方式三的优缺点以及建议
优点:相对于撰写方式一,更简要并且满足“判断是否达到预设停止条件”这一步骤的执行时间的灵活性要求;相对于撰写方式二,克服了因“及其后续步骤”这一内容所导致的不清楚。
缺点:
(1)不清楚,其理由为:因“在达到预设停止条件时”这一技术特征中出现的“预设停止条件”这一内容属于自造词,以使该技术特征无法准确地表示出何时停止训练,从而使得采用撰写方式三所撰写的权利要求的保护范围不清楚,进而使得日后可能会面临一些风险。
(2)限定性强,其理由为:非首轮训练过程中所执行的步骤也是可以灵活设置的,如非首轮训练过程中所执行的步骤包括图1中S1-S4,或者,非首轮训练过程中所执行的步骤包括图1中S2-S4等,如此使得采用撰写方式三所撰写的权利要求容易无法覆盖一些可能的实施方式,从而导致权利要求的保护范围受到影响。
建议:相较于撰写方式一和撰写方式二,本文更推荐撰写方式三。
基于上文撰写方式一、撰写方式二以及撰写方式三的相关内容可知,这三种方式的部分或者全部缺点均来自于用于限定迭代循环这一过程的技术特征。然而,因通过迭代循环方式实现模型训练是一种比较常规的技术手段,以使涉及人工智能的发明专利申请的发明点通常很少出现在迭代循环方式上,而是大部分出现在其他地方,如类似于图1中S2这类的用于对样本数据进行前期处理的步骤和/或类似于图1中S3这类的用于借助模型进行数据处理的步骤等地方;还因这些地方通常会出现在某一轮训练过程或者每一轮训练过程,故可以通过限定一轮训练过程的方式进行发明点保护。基于此,本文给出了一种新的撰写方式,也就是,下文撰写方式四。
撰写方式四
1.一种模型更新方法,其特征在于,所述方法包括:
获取样本数据和所述样本数据对应的标签数据;
对所述样本数据进行第一处理,得到第一处理结果;
利用机器学习模型对所述第一处理结果进行第二处理,得到第二处理结果;
依据所述第二处理结果和所述标签数据之间的差距,更新机器学习模型中的模型参数。
撰写方式四的优缺点以及建议
优点:
(1)相对于撰写方式一至撰写方式三,更简要并且克服了这些撰写方式的所有缺点。
(2)扩大了保护范围,其理由为:因“一种模型更新方法”这一技术特征只是限定了权利要求所保护的方法用于实现模型更新处理,未限定应用领域必须是模型训练这一领域,以使该权利要求所保护的方法适用于任一具有模型更新需求的领域。
缺点:撰写方式四不适于保护迭代更新方式方面的发明点。
建议:相较于撰写方式一、撰写方式二、以及撰写方式三,本文更推荐撰写方式四。
另外,对于上文撰写方式一、撰写方式二、撰写方式三以及撰写方式四来说,这四种撰写方式均涉及了“更新机器学习模型中的模型参数”这一技术特征,而且这个技术特征能够准确地限定出模型更新时需要更新什么信息。然而,随着人工智能技术的不断发展,模型的更新不再局限于通过参数更新的方式进行实现,还可以通过增加网络模块的方式,如lora微调进行实现,以使“更新机器学习模型中的模型参数”这一技术特征无法涵盖这种新增的模型更新方式。基于此,本文给出了一种新的撰写方式,也就是,下文撰写方式五。
撰写方式五
1.一种模型更新方法,其特征在于,所述方法包括:
获取样本数据和所述样本数据对应的标签数据;
对所述样本数据进行第一处理,得到第一处理结果;
利用机器学习模型对所述第一处理结果进行第二处理,得到第二处理结果;
依据所述第二处理结果和所述标签数据之间的差距,更新机器学习模型。
撰写方式五的优缺点以及建议
优点:克服了上文“更新机器学习模型中的模型参数”这一技术特征所导致的缺陷,如无法涵盖通过增加网络模块方式实现模型更新的技术方案。
缺点:撰写方式五不适于保护迭代更新方式方面的发明点。
建议:相较于撰写方式一、撰写方式二、撰写方式三以及撰写方式四,本文更推荐撰写方式五。
基于上文五种撰写方式的相关内容可知,对于涉及人工智能的发明专利申请来说,如果该申请的发明点能够借助一轮训练过程说清楚,则可以采用上文撰写方式五撰写该申请的独立权利要求;如果该申请的发明点必须借助多轮训练过程才能说清楚,则可以优先选择类似于上文撰写方式三的撰写方式撰写该申请的独立权利要求;如果该申请的发明点不涉及模型更新内容,则可以选择使用“更新机器学习模型”这一技术特征撰写该申请的独立权利要求。
以上是笔者的一些个人经验总结,如有不妥之处,还请读者批评指教。
相关关键词
公司总部
机构代码:11227
地址:北京市朝阳区建国门外大街22号赛特广场七层
邮编:100004
总部电话:(8610)59208888
电子邮箱:mail@unitalen.com
邮件新闻接收
不要错过我们提供的中国区知识产权保护的相关信息、服务和活动通知
提交将接受我们特别的服务优惠和知识产权保护咨询的电子邮件




法律声明 Unitalen Mail Box ©2016 Unitalen Attorneys at Law 版权所有 集佳知识产权代理有限公司 京ICP备11033076号 京公网安备11010502020670